设为首页
优惠IDC
收藏本站
六狼博客
六狼论坛
开启辅助访问
切换到窄版
用户名
Email
自动登录
找回密码
密码
登录
立即注册
只需一步,快速开始
只需一步,快速开始
快捷导航
门户
首页
BBS
云计算
大数据
手机
移动开发android,ios,windows phone,windows mobile
编程
编程技术java,php,python,delphi,ruby,c,c++
前端
WEB前端htmlcss,javascript,jquery,html5
数据库
数据库开发Access,mysql,oracle,sql server,MongoDB
系统
操作系统windows,linux,unix,os,RedHat,tomcat
架构
项目管理
软件设计,架构设计,面向对象,设计模式,项目管理
企业
服务
运维实战
神马
搜索
搜索
热搜:
php
java
python
ruby
hadoop
sphinx
solr
ios
android
windows
centos
本版
帖子
用户
六狼论坛
»
首页
›
项目管理
›
计算机图形学
›
OpenCL 学习step by step (9) 灰度图Histogram计算(3) ...
返回列表
查看:
951
|
回复:
0
OpenCL 学习step by step (9) 灰度图Histogram计算(3)
[复制链接]
迈克老狼2012
迈克老狼2012
当前离线
积分
474
窥视卡
雷达卡
升级
91.33%
当前用户组为
举人
当前积分为
474
, 升到下一级还需要 26 点。
154
主题
154
主题
154
主题
举人
举人, 积分 474, 距离下一级还需 26 积分
举人, 积分 474, 距离下一级还需 26 积分
积分
474
发消息
楼主
|
发表于 2012-12-30 11:53:13
|
显示全部楼层
|
阅读模式
OpenCL 学习step by step (9) 灰度图Histogram计算(3)
<div class="postbody"><div id="cnblogs_post_body">
     在opencl编程中,特别是基于gpu的opencl的编程,提高程序性能最主要的方法就是想法提高memory的利用率:一个是提高global memory的合并读写效率,另一个就是减少local memory的bank conflit。下面我们分析一下教程7中的代码,其的memory利用率如何?
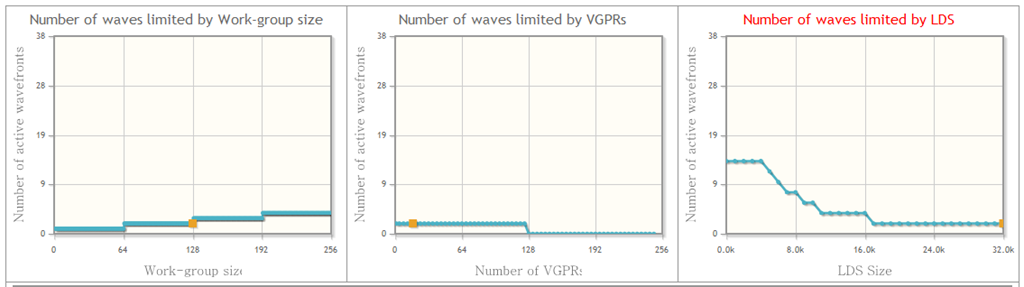
    首先我们用amd的opencl profiler分析一下程序性能(不会找不到用吧,点击view-other windows-app profiler…,然后就看到了…)。
     下面我们来分析我们的kernel代码中memory操作:
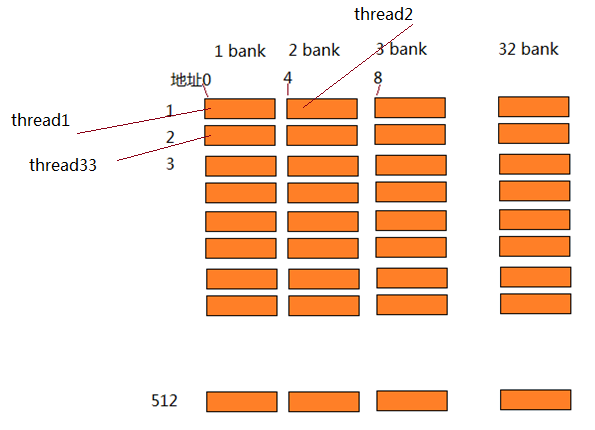
     首先是shared memory的的初始化,我们知道shared memory是local memory,被一个workgroup中的所有thread,或者说work item共享。在amd硬件系统中,local memory是LDS,它通常是为32k,分为32个bank,dword字节地址,每个bank 512个item,我们可以通过函数得到自己系统中的local memory数量:
cl_ulong DeviceLocalMemSize;
clGetDeviceInfo(device,
    CL_DEVICE_LOCAL_MEM_SIZE,
    sizeof(cl_ulong),
    &DeviceLocalMemSize,
    NULL);
lds的示意图如下,对于每个bank,同时只能有一个读写请求,如果两个thread都读写bank1,那个必须串行访问,这就称作bank conflict。
kernel初始化local memory的代码如下:
//初始化共享内存
for(int i = 0; i < BIN_SIZE; ++i)
    sharedArray[localId * BIN_SIZE + i] = 0;
     在同一时间,thread0访问地址0(bank1),thread1,访问地址256,也在bank1,…,这样就有很多bank conflit,降低程序的性能。从profiler里面可以看到,lds bank conflit为13.98,很高的比例,所以此时同时运行的thread就比较少,只有总wave(每个wave 64个thread)的12%(我曾经默认lds内存分配是0,这样我们就省去了这些代码,但是实际上分配内存是一些随机的值…)。
第二段memory操作的代码为:
 
   //计算thread直方图
    for(int i = 0; i < BIN_SIZE; ++i)
    {
        uint value = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId];
        sharedArray[localId * BIN_SIZE + value]++;
    }
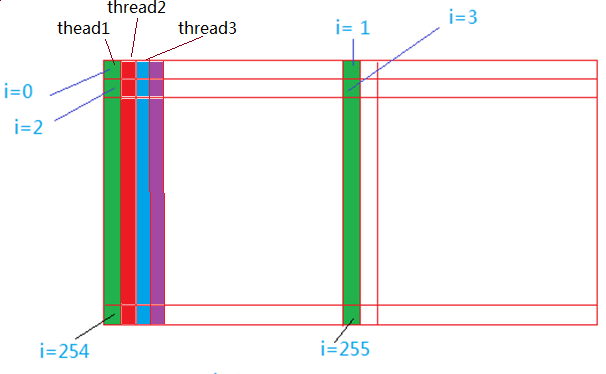
其中有lds的操作,也有global memory的操作,对于全局memory的访问,在同一时刻,thread0访问i=0的memory
,thread1访问相邻的memory单元…,这是对于global memory的访问会采用合并读写的方式(coalencing),就是一个memory请求返回16个dword,也就是一个请求满足16个thread,提高memory利用率。此时对lds的写是随机的,根据value的值决定,不能控制…
 
最后一段memory读写的代码:
//合并workgroup中所有线程的直方图,产生workgroup直方图
for(int i = 0; i < BIN_SIZE / groupSize; ++i)
{
     uint binCount = 0;
     for(int j = 0; j < groupSize; ++j)
         binCount += sharedArray[j * BIN_SIZE + i * groupSize + localId];
        
     binResult[groupId * BIN_SIZE + i * groupSize + localId] = binCount;
}
其中lds的读写如下图,此时每个线程访问不同的bank,因为amd lds访问就是以32为单位,所以实际上,这段代码不会有bank conflit。
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
显身卡
返回列表
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
本版积分规则
发表回复
回帖后跳转到最后一页
Copyright © 2008-2020
六狼论坛
(http://it.6wolf.com) 版权所有 All Rights Reserved.
Powered by
Discuz!
X3.4
京ICP备14020293号-2
本网站内容均收集于互联网,如有问题请联系
QQ:389897944
予以删除
快速回复
返回顶部
返回列表



 窥视卡
窥视卡 雷达卡
雷达卡

 楼主
楼主

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡