|
|
OpenCL 学习step by step (7) 灰度图Histogram计算(1)
“     histogram翻译成中文就是直方图,在计算机图像处理和视觉技术中,通常用histogram来进行图像匹配,从而完成track,比如meanshift跟踪算法中,经常要用到图像的直方图。
     灰度图的histogram计算,首先要选择bin(中文可以称作槽)的数量,对于灰度图,像素的范围通常是[0-255],所以bin的数目就是256,然后我们循环整幅图像,统计出每种像素值出现的次数,放到对应的bin中。比如bin[0]中放的就是整幅图像中灰度值为0的像素个数,bin[1]中放的就是整幅图像中灰度值为1的像素个数……
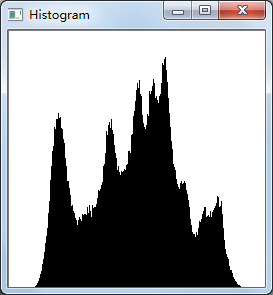
     下面的直方图就是灰度图lenna对应的直方图。
 
      灰度图直方图的cpu计算特别简单,定义一个数组hostBin[256],初始化所有数组元素为0,然后循环整幅图像,得到直方图,代码如下:
//cpu求直方图
void cpu_histgo()
    {
    int i, j;
    for(i = 0; i < height; ++i)
        {
        for(j = 0; j < width; ++j)
            {
            //printf("data: %d\n", data[i * width + j] );
            hostBin[data[i * width + j]]++;
            //printf("hostbin %d=%d\n", data[i * width + j], hostBin[data[i * width + j]]);
            }
        }
    }
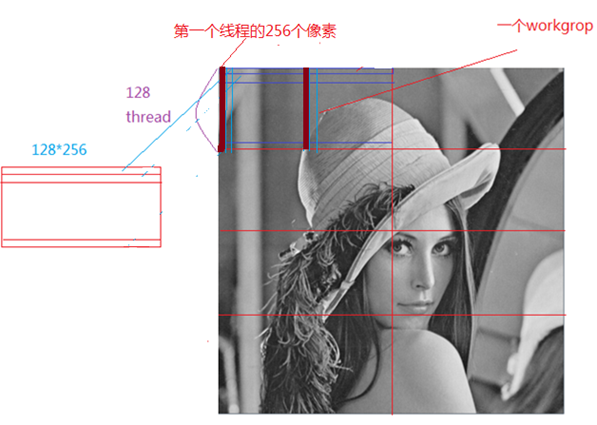
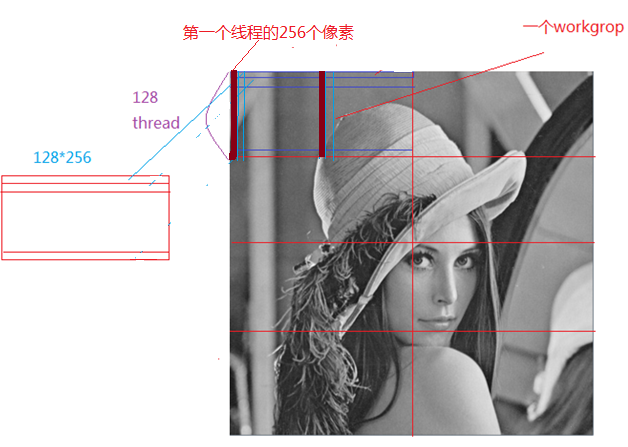
    如何使用opencl,来计算灰度图,就没有那么简单了。我们知道gpu的优势是并行计算,如何把图像分块,来并行计算直方图,是我们讨论的重点。下面是一副512*512图像的thread,workgroup划分:

     我们设定图像的宽度是bins的整数倍,即256的倍数,高度是workgroup size(本程序中,设置为128)的倍数,如果图像高宽不是bins和workgroup size的倍数,则我们通过下面的公式把图像的宽度和高度变成它们的倍数:
//width是binSize的整数倍,height是groupsize的整数倍
width = (width / binSize ? width / binSize: 1) * binSize;
height = (height / groupSize ? height / groupSize: 1) * groupSize;
     则512*512的图像可以分为8个work group,每个workgroup包括128个thread,每个thread计算256个像素的直方图,并把结果放到该thread对应的local memroy空间,在kenrel代码结束前,合并一个workgroup中所有thread的直方图,生成一个workgroup块的直方图,最后在host端,合并8个workgroup块的直方图,产生最终的直方图。
    openCL的memory对象主要有3个,dataBuffer用来传入图像数据,而minDeviceBinBuf大小是workgroup number *256, 即每个workgroup对应一个bin,另外一个kernel函数的第二个参数,它的大小为workgroup size*256, 用于workgroup中的每个线程存放自己256个像素的直方图结果。
//创建2个OpenCL内存对象
dataBuf = clCreateBuffer(
    context,
    CL_MEM_READ_ONLY,
    sizeof(cl_uchar) * width  * height,
    NULL,
    0);
//该对象存放每个block块的直方图结果
midDeviceBinBuf = clCreateBuffer(
    context,
    CL_MEM_WRITE_ONLY,
    sizeof(cl_uint) * binSize * subHistgCnt,
    NULL,
    0);
   …
    status = clSetKernelArg(kernel, 1, groupSize * binSize * sizeof(cl_uchar), NULL); //local memroy size, lds for amd
下面看看kernel代码是如何计算workgroup块的直方图。
__kernel
void histogram256(__global const uchar* data,
                  __local uchar* sharedArray,
                  __global uint* binResult)
{
    size_t localId = get_local_id(0);
    size_t globalId = get_global_id(0);
    size_t groupId = get_group_id(0);
    size_t groupSize = get_local_size(0);
下面这部分代码初始化每个thread对应的local memory,也就是对应的256个bin中计数清零。sharedArray大小是workgroup size * 256 = 128 * 256
    //初始化共享内存
    for(int i = 0; i < BIN_SIZE; ++i)
        sharedArray[localId * BIN_SIZE + i] = 0;
通过barrier设置workgroup中所有thread的同步点,保证所有thread都完成初始化操作。
    barrier(CLK_LOCAL_MEM_FENCE);
   
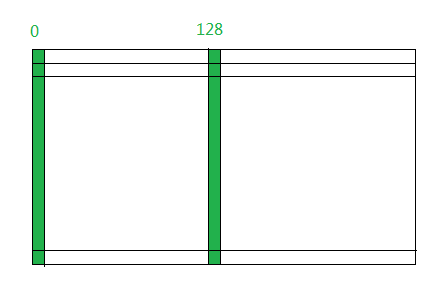
下面的代码,计算thread中,256个像素的直方图,比如对于workgroup 0中的thread 0它计算的256个像素为绿条的部分像素,注意:每个thread的包含的像素并不是连续的。

    //计算thread直方图
    for(int i = 0; i < BIN_SIZE; ++i)
    {
        uint value = (uint)data[groupId * groupSize * BIN_SIZE + i * groupSize + localId];
        sharedArray[localId * BIN_SIZE + value]++;
    }
    通过fence,保证每个thread都完成各自的直方图计算。
    barrier(CLK_LOCAL_MEM_FENCE); 
    下面是合并各个thread的直方图形成整个workgroup像素块的直方图,每个thread合并2个bin,比如thread 0,合并bin0和bin128。

   //合并workgroup中所有线程的直方图,产生workgroup直方图
    for(int i = 0; i < BIN_SIZE / groupSize; ++i)
    {
        uint binCount = 0;
        for(int j = 0; j < groupSize; ++j)
            binCount += sharedArray[j * BIN_SIZE + i * groupSize + localId];
           
        binResult[groupId * BIN_SIZE + i * groupSize + localId] = binCount;
    }
}
最终在host端,我们还要把每个workgroup块的直方图合并成得到整个图像的直方图,主要代码如下:
// 合并子块直方图值
for(i = 0; i < subHistgCnt; ++i)
    {
    for( j = 0; j < binSize; ++j)
        {
        deviceBin[j] += midDeviceBin[i * binSize + j];
        }
    }
完整的代码请参考:
工程文件gclTutorial7
代码下载:
http://files.cnblogs.com/mikewolf2002/gclTutorial.zip |
|



 窥视卡
窥视卡 雷达卡
雷达卡

 楼主
楼主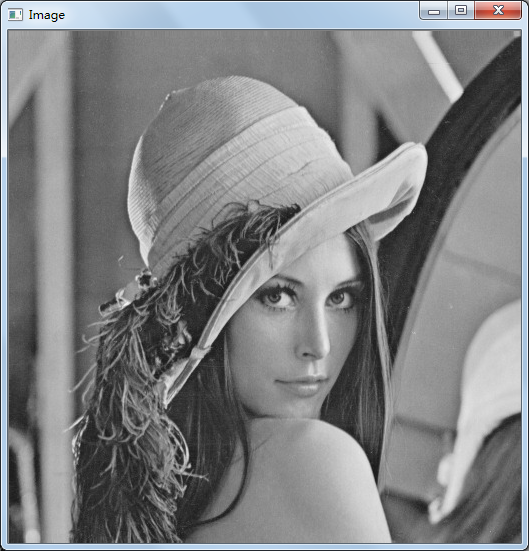


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡